Overview
In a multicenter study, our ODAC algorithm allows researchers to fit a Cox regression model across multiple data sets, without the need of directly sharing subject-level information. The Cox regression model is a commonly used approach to model a time-to-event outcome and a set of explanatory variables, which is a foundational method for studying associations, causal effects, and predicting risk of a certain event. Before conducting the multicenter analysis, all datasets have to be converted to a unified format where all the variables are defined in a standard way (e.g, OMOP Common Data Model). We require one of the sites to be the coordinating site, and the rest to be the participating sites. The coordinating site is responsible for obtaining and broadcasting the initial value of model parameters, synthesizing information obtained from other sites, and obtaining the final results. The participating sites only need to calculate the aggregated data and transfer them to the coordinating site. A more detailed description is provided below.
Cox Regression Model
Suppose we have K sites, and the coordinating site is the first site. Let \(X\) be a vector denoting \(p\) risk factors and let \(T\) be the time-to-event for the outcome of interest. The Cox model assumes the hazard at time t follows
\(\lambda(t|X) = \lambda_{0}(t)exp(\beta^{T}X)\)
where \(\lambda_{0}(t)\) is the baseline hazard function and \(\beta\) is the vector of intercept and regression coefficients.
Algorithm
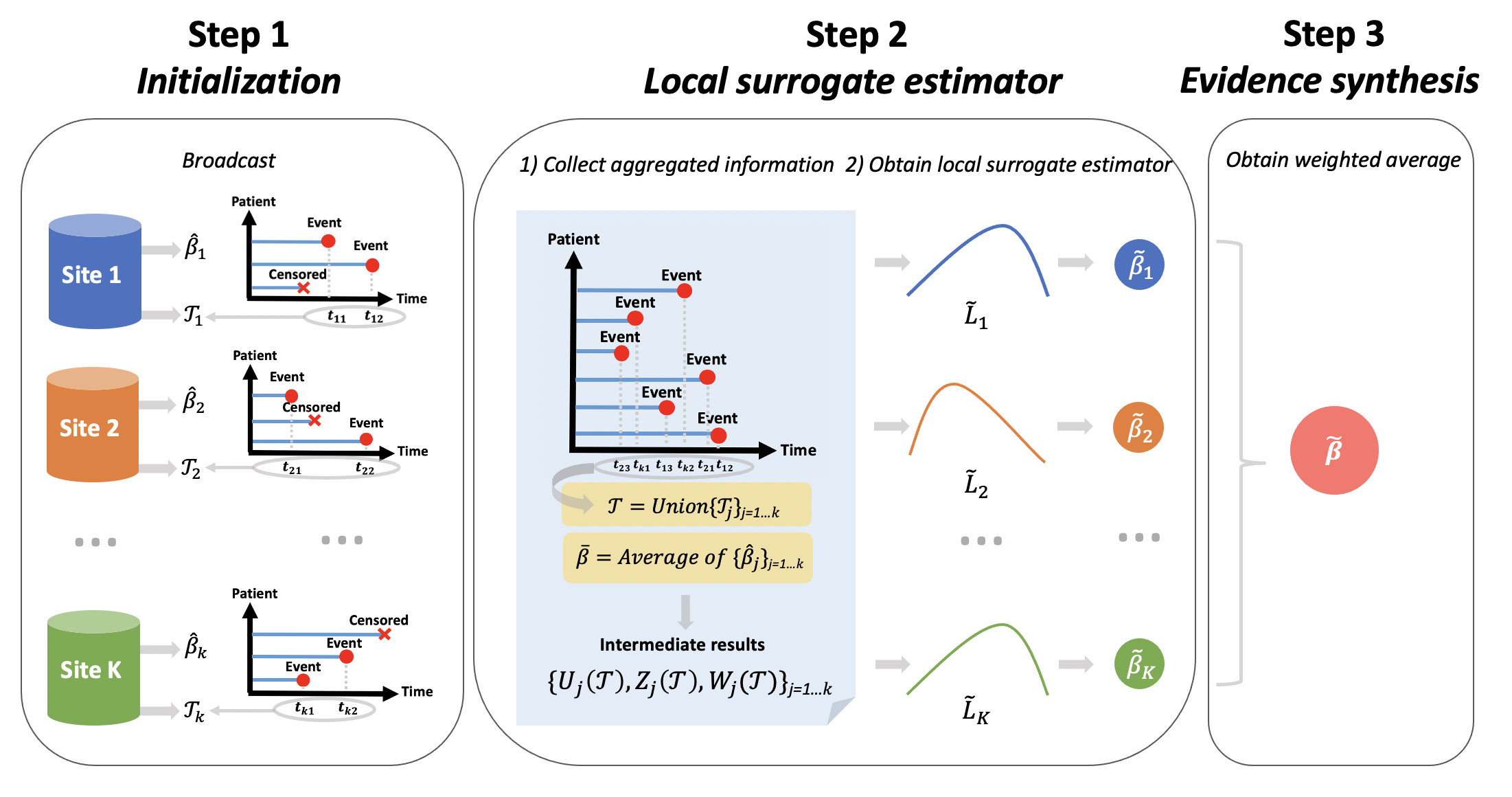 Our algorithm has three steps:
Our algorithm has three steps:
- First, the coordinating site fits a logistic regression model using its own data, and share the estimates of regression coefficients \(\bar{\beta}\) to the participating sites.
- Second, each participating site calculates the first, and the second order gradients of their own likelihood function, which are evaluated at the initial value \(\bar{\beta}\). Explicit form of calculating these two terms can be found in [1]. These aggregate data are then transferred to the coordinating site.
- Third, the coordinating site uses the aggregate information and it own individual level data to obtain an improved estimate of \(\beta\).
Figure 2 below give an example of the information shared in each step in a setting with one explanatory variable in the model.
 Sample code
Sample code
Set the “control” in R as beow to start ODAC algorithm
control <- list(project_name ='Lung cancer study',
step = 'initialize',
sites = c('site1', 'site2', 'site3'),
heterogeneity = FALSE,
model = 'ODAC',
family = 'cox',
outcome = "Surv(time, status)",
variables = c('age', 'sex'),
optim_maxit = 100,
lead_site = 'site1',
upload_date = as.character(Sys.time()) )
demo(ODAC)
Reference
[1] Duan, R., Luo, C., Schuemie, M.J., Tong, J., Liang, J., Boland, M.R., Bian, J., Xu, H., Berlin, J.A., Moore, J.H., Mahoney, K.B. and Chen, Y., (2020). Learning from local to global – an efficient distributed algorithm for modeling time to event data. Journal of the American Medical Informatics Association (in press).
[2] Duan, R., Chen Z., Tong, J., Luo, C., Lyu, T., Tao, C., Maraganore, D., Bian, J. and Chen, Y.. Leverage real-world longitudinal data in large clinical research networks for Alzheimer’s disease and related dementia. AMIA Annu Symp Proc. 2020 (in Press).